RabbitMQ vs Kafka: 어떤 메시징 시스템을 선택해야 할까?
rabbitMQ와 Kafka의 차이점을 설명하고 어떤 상황에서 선택해야하는지 소개합니다.
주요 차이점
1. 처리 방식
- RabbitMQ: FIFO 기반, 큐 구조
- 메시지는 생산된 순서대로 큐에 쌓이고, 컨슈머가 순서대로 처리합니다.
- 구조적으로 직렬 처리가 기본이며, 순서 보장이 중요할 때 유리합니다.
- Kafka: 파티셔닝 기반, 병렬 처리 특화
- 토픽은 여러 파티션으로 나뉘고, 각 파티션은 독립적로 처리됩니다.
- 대량의 데이터를 병렬로 처리할 수 있어 높은 처리량 확보가 가능합니다.
2. 메시지 보관 방식
- RabbitMQ
- 기본적으로 메시지는 컨슘 후 즉시 삭제됩니다.
- 필요 시 큐에 TTL 설정으로 보관 기간을 제한할 수 있지만, 메시지 보존 목적의 구조는 아닙니다.
- Kafka
- 기본적으로 메시지를 보관합니다. 보관 기간을 설정할 수 있으며(기본 7일), 디스크가 허용하는 한 더 길게도 가능합니다.
각 컨슈머 그룹의 오프셋(offset)을 기준으로 어떤 메시지를 읽었는지 추적 가능합니다.
tps-test토픽에 대한 컨슈머 그룹이 2개가 있다고 했을 때 서로 현재의 오프셋current-offset을 다르게 저장하고 있는걸 아래 그림처럼 확인이 가능합니다.

3. Push vs Pull 모델
- RabbitMQ: Push 모델
- 브로커가 컨슈머에게 메시지를 자동으로 푸시합니다.
- 컨슈머의 처리 속도가 따라가지 못하면 병목이 발생할 수 있습니다.
- Kafka: Pull 모델
- 컨슈머가 필요할 때 메시지를 직접 가져오는 구조입니다.
컨슈머 애플리케이션의 처리 속도에 맞춰 조절 가능, 유연한 흐름 제어 가능합니다.
1
configs.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "100"); // 레코드(메시지) 100개씩 가져와 처리 설정
4. 수평 확장성
- RabbitMQ
- 큐 단위로 메시지를 저장하므로 하나의 큐는 단일 처리 흐름을 따릅니다.
- 여러 컨슈머가 하나의 큐를 구독하면 라운드 로빈 방식으로 메시지를 나눠받지만, 구조적 확장성은 제한적입니다.
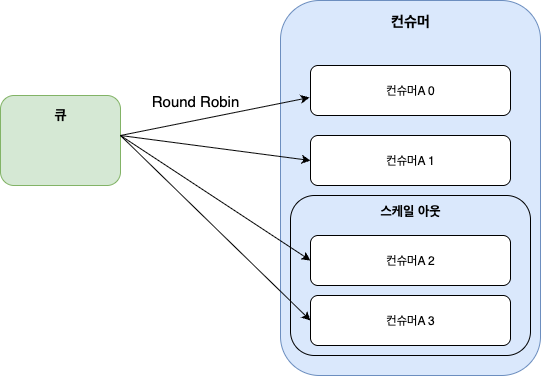
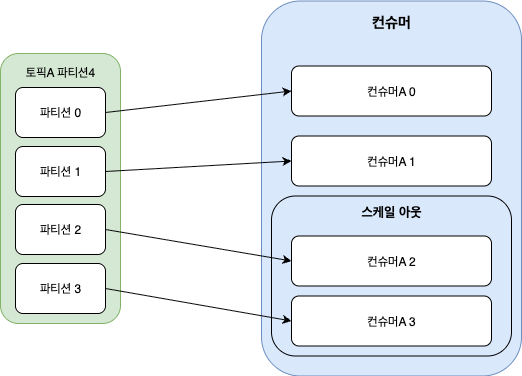
- Kafka
- 파티션을 기준으로 토픽을 분산할 수 있어 수평 확장으로 처리량을 높일 수 있습니다.
어떤 기술을 선택해야 할까?
결정은 서비스의 특성과 요구 사항에 따라 달라집니다.
RabbitMQ를 선택해야 하는 경우
- 러닝 커브가 낮고, 개발 난이도가 낮은 메시징 솔루션이 필요할 때
- 순서 보장이 중요한 워크플로우 처리
- 복잡한 라우팅 로직 (예: 팬아웃, 라우팅키 기반 멀티 캐스팅)
- 낮은 지연시간(latency)이 중요한 요청/응답 구조
Kafka를 선택해야 하는 경우
- 대용량 메시지 처리가 필요한 환경 (로그 수집, 실시간 분석 등)
- 이벤트 소싱 / 이벤트 기반 아키텍처 도입이 필요한 시스템
- 메시지를 장기간 저장하거나 나중에 다시 처리할 수 있어야 하는 경우
- 고속의 데이터 스트리밍 처리 및 확장성 확보가 중요한 경우
RabbitMQ Streams
RabbitMQ는 3.9 버전부터 RabbitMQ Streams 기능을 도입하여 Kafka와 유사하게 삭제되지 않는 메시지 보관 **기능을 지원합니다.
다만, 이 기능은 기존 AMQP 방식과는 다르며, 별도의 API와 구성을 필요로 합니다.
- 고속 스트리밍 처리
- 메시지의 오프셋 기반 소비
- 디스크 기반 메시지 저장
이로써 RabbitMQ는 기존의 장점은 유지하면서, 보관형 메시지 처리까지 확장 가능한 형태로 진화하고 있습니다.
This post is licensed under CC BY 4.0 by the author.