3,500만건 DB 데이터 지연쿼리 개선기
3,500만건 DB 데이터 지연쿼리 개선을 어떻게 적용했는지에 대해 소개합니다.
이슈: 타임라인 쿼리에서 특정 조건 검색 시 costs가 높아 지연
특정 앱의 타임라인 조회 API에서 지연 발생 및 높은 costs가 확인되었습니다. 하루 약 1만 3천 건의 요청 중, 응답 시간이 2초 이상 소요된 요청은 96건으로 비율은 낮지만, 최대 응답 시간이 55초에 달해 문제가 됩니다. 이로 인해 DB 서버 성능 저하를 초래할 수 있어, 쿼리 성능 개선 작업을 진행하기로 했습니다.
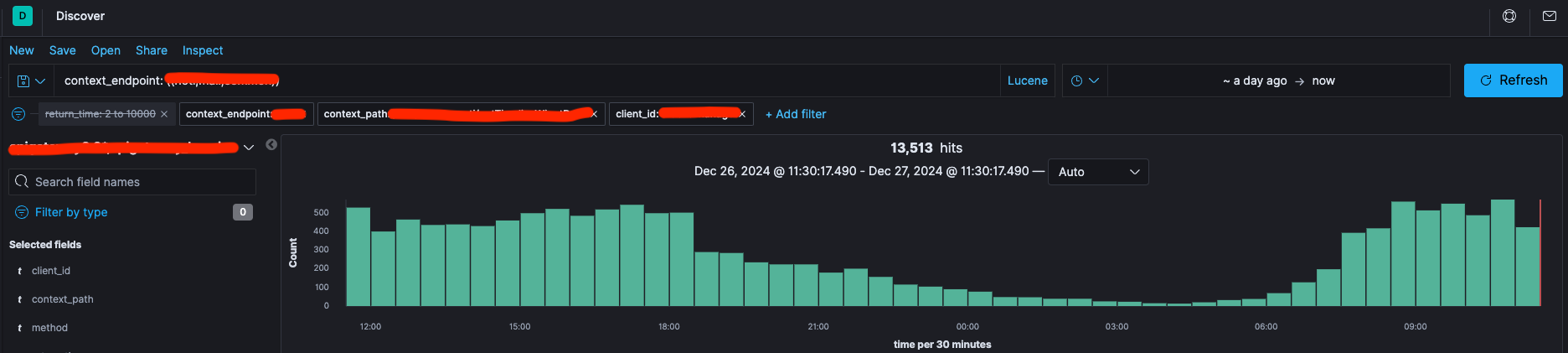

costs 높은 쿼리
1
2
3
4
5
6
7
8
9
10
11
12
SELECT *
FROM t_timeline
WHERE 1=1
AND portal_id = 'test'
AND company_no IN (258850, -1)
AND is_deleted = 'F'
AND ( service_code IN ('service1')
OR 'app' = ANY (regexp_split_to_array(target_platform , ',')))
AND insert_timestamp::timestamp < '2024-12-09 00:00:00'::timestamp
AND insert_timestamp::timestamp > '2024-06-12 10:45:06'::timestamp
ORDER BY st DESC
LIMIT 50::BIGINT
테이블 설명
사용자 ID, 회사, 서비스 기준에서 타임라인 데이터를 등록하고 있었습니다. 하지만 새로운 앱(platform)들이 생기면서 기존 서비스 정책에 맞지 않아 해당 app에서 조회될 수 있도록 target_platform 컬럼을 추가하게 되었습니다.
target_platform에는 여러 platform이 들어 갈 수 있으므로 콤마(,)로 구분하여 저장하고 있습니다.
예) target_platform: app1, app2
기존 index
1
CREATE INDEX ixn_timeline__concatenated01 ON t_timeline USING btree (company_no, portal_id, service_code, insert_timestamp DESC)
문제점
target_patform 조건이 추가된 쿼리가 OR 조건으로 조회되고 있기 때문에 기존 index로는 속도가 안나오는 문제점이 확인되었습니다.
개발 costs 
운영 costs 
개선방안:
쿼리를 개선하기 위해 해결방안은 둘중 하나를 선택해서 개선하기로 하였습니다.
- 테이블에 target_platform 컬럼을 정규화 시켜 JOIN 쿼리로 변경하여 지연쿼리 개선
- 지연되는 쿼리 index 추가하여 개선
개선 방안 검토:
1. 테이블을 정규화 시켜 JOIN 쿼리로 변경하여 지연쿼리 개선 방안
정규화 이후 복합 인덱스 생성
1
CREATE INDEX ixn_timeline__concatenated03 ON t_timeline USING btree (connect_key, portal_id, company_no)
정규화된 테이블을 JOIN하여 실행 계획 확인 시 costs 및 생성된 복합 index가 제대로 안타는 문제 발생
1
2
3
4
5
6
7
8
9
10
EXPLAIN ANALYZE
SELECT *
FROM t_timeline t
INNER JOIN t_target_platform tp
ON t.connect_key = tp.connect_key
AND tp.target_platform = 'app'
AND t.portal_id = 'test'
AND t.company_no IN (12124, -1)
AND insert_timestamp::timestamp < '2024-12-09 00:00:00'::timestamp
AND insert_timestamp::timestamp > '2024-06-12 10:45:06'::timestamp

🤔join 할때 생성된 복합 index에서 connect_key부터 스캔하지 않을까?

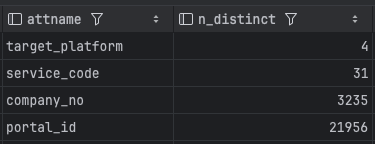
고유 값 비율(n_distinct)을 확인한 결과, connect_key의 값이 -1로 설정되어 있어 해당 컬럼의 값이 테이블 전체 행(row) 수만큼 고유한 것으로 추정됩니다. 이로 인해, 복합 인덱스의 선두에 connect_key를 선언하더라도 데이터의 선택도가 낮아 테이블 전체를 스캔해야 하는 상황으로 판단됩니다. 따라서 PostgreSQL은 보다 효율적인 필터링이 가능한portal_id와company_no를 기준으로 인덱스 스캔을 수행합니다.
2. 지연되는 쿼리 index 추가하여 개선 진행 방안
GIN index 생성 방안
GIN index 생성하여 배열형태로 데이터를 만들어 조회했을 때 costs가 어느 정도 감소
11555 → 7861 costs 감소 (31% 비용 감소)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
ALTER TABLE t_timeline add COLUMN target_platform_array TEXT[]; UPDATE t_timeline SET target_platform_array = regexp_split_to_array(target_platform, ','); CREATE INDEX ixn_timeline__target_platform_array_gin ON t_timeline USING GIN (target_platform_array); SELECT * FROM t_timeline WHERE 1=1 AND portal_id = 'test' AND company_no IN (258850, -1) AND is_deleted = 'F' AND ( service_code IN ('service1') OR target_platform_array @> ARRAY['app'] ) AND insert_timestamp::timestamp < '2024-12-09 00:00:00'::timestamp AND insert_timestamp::timestamp > '2024-06-12 10:45:06'::timestamp ORDER BY st DESC LIMIT 50::BIGINT

시스템 특성상 조회보다 INSERT/UPDATE가 많아 gin index 사용 시 INSERT/UPDATE 성능에 영향이 미치므로 gin index 생성은 맞지 않는 index 판단되었습니다.
복합 index 추가 생성 방안
기존에 사용하는 플랫폼에서는 대부분
NULL값이 저장되어 있으며, 신규 플랫폼에 대해서만 값이 설정되는 구조임을 확인하였습니다. 현재 데이터에서target_platform의 값 비율을 분석한 결과,NULL값이 대부분을 차지하는 것으로 나타났습니다.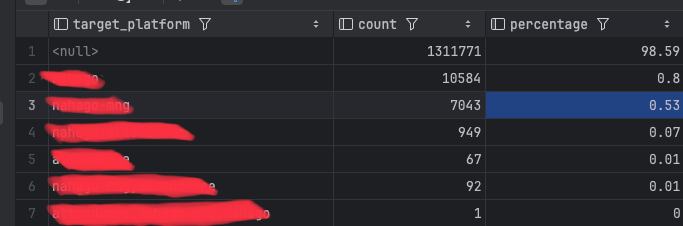
NULL은 “아직 정해지지 않은 값“이므로target_platform을 포함한 복합 index를 생성1
CREATE INDEX ixn_timeline__concatenated02 ON t_timeline USING btree (portal_id, company_no, service_code, target_service_code)
index 순서는 카디널리티(특정 컬럼이 가지는 고유 값의 수)를 확인하여 생성하였습니다.
결과:
정규화, GIN index 생성 방안으로 검토 했을 때는 costs에 변화가 없는걸로 확인되어 복합 index 추가 생성 방안으로 반영하였습니다. 개발/운영 속도 전후 변화 비교는 아래와 같습니다
개발: 11555 → 602 costs 감소 (94% 비용 감소)

운영: 64691 → 6160 costs 감소 (90% 비용 감소)

운영 반영 이후, 하루 평균 1만 3천 건 중 2초 이상 지연된 건수는 5건으로 줄었으며, 최대 55초까지 걸리던 응답 시간 문제는 해소되었습니다. 개선된 지연 건수의 응답 시간은 2~3초로 단축되었습니다.
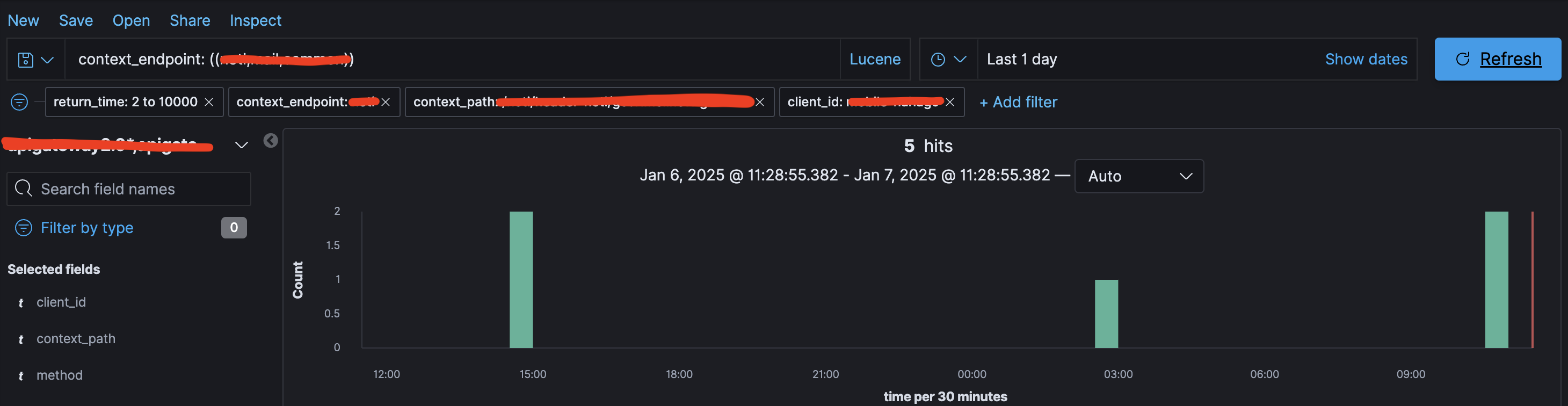
느낀점:
이번 작업을 통해 데이터베이스 성능 최적화에서 ‘정석’이 항상 최선은 아님을 깨달았습니다. 대용량 데이터를 다룰 때는 데이터 특성을 이해하고 맞춤형 인덱스 전략을 수립하는 것이 더 효과적이라는 점을 실감했습니다.
특히 target_platform 컬럼의 특성을 분석해 복합 인덱스를 적용한 결과, 개발 환경에서 94%의 비용을 절감할 수 있었습니다. 또한, GIN 인덱스처럼 효과적인 방법이라도 INSERT/UPDATE가 빈번한 시스템에서는 부적합하다는 점도 확인했습니다.
이번 경험은 데이터 설계와 성능 최적화에서 데이터 중심적인 접근이 얼마나 중요한지 다시금 깨닫게 해준 계기가 되었습니다.